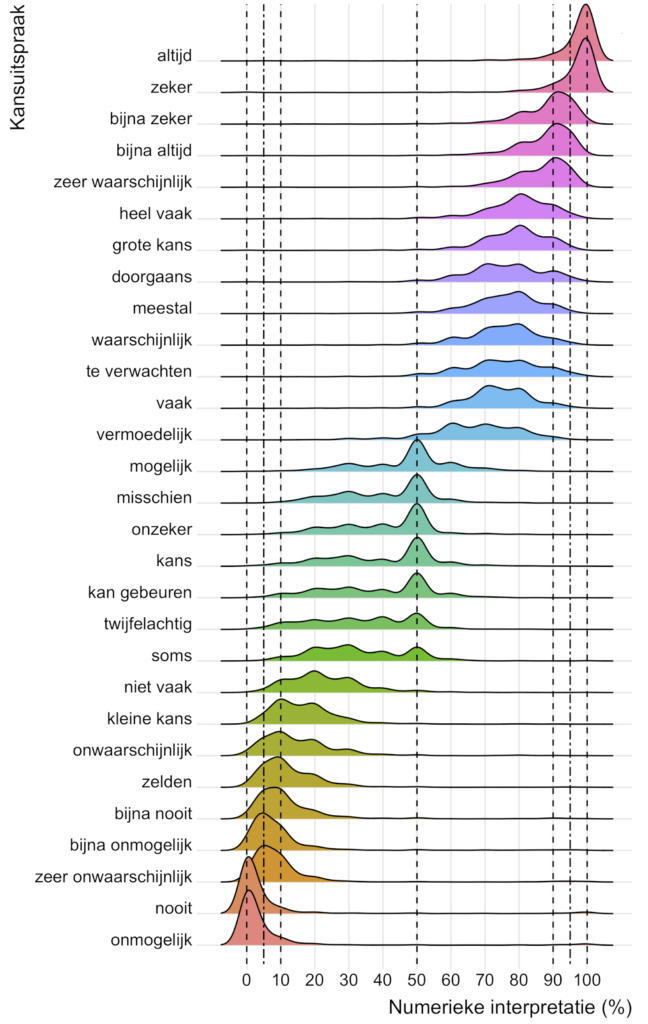
Back in 2011 I wrote about “words of estimative probability“; the quantitative ranges we apply to ambiguous words and phrases, based on Sherman Kent’s research for the CIA in the 1960s.
In 2015, Reddit user zonination duplicated the study using /r/samplesize. His resulting post in /r/dataisbeautiful made the longlist for the 2015 Kantar Information is Beautiful Awards:
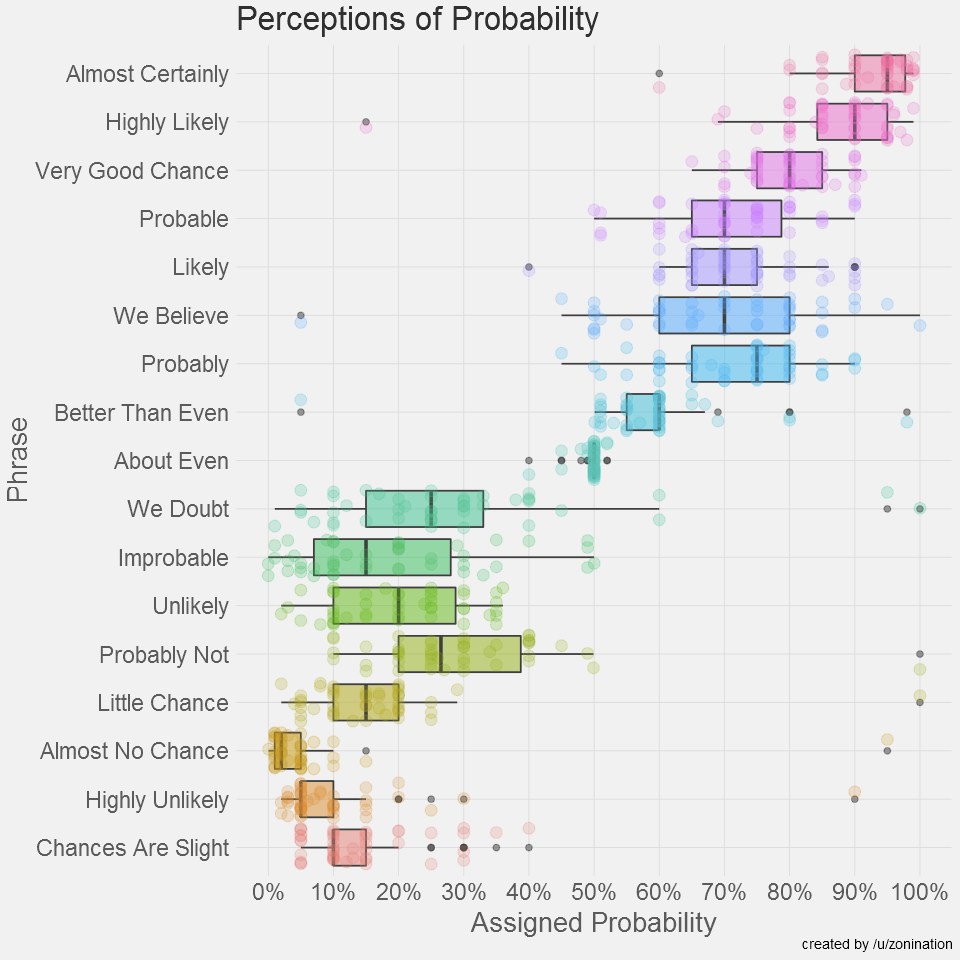
They have since updated their diagrams to beautiful ridgeline / joy plots, making the data fantastically easy to understand (and much more shareable to those not used to reading statistical plots):
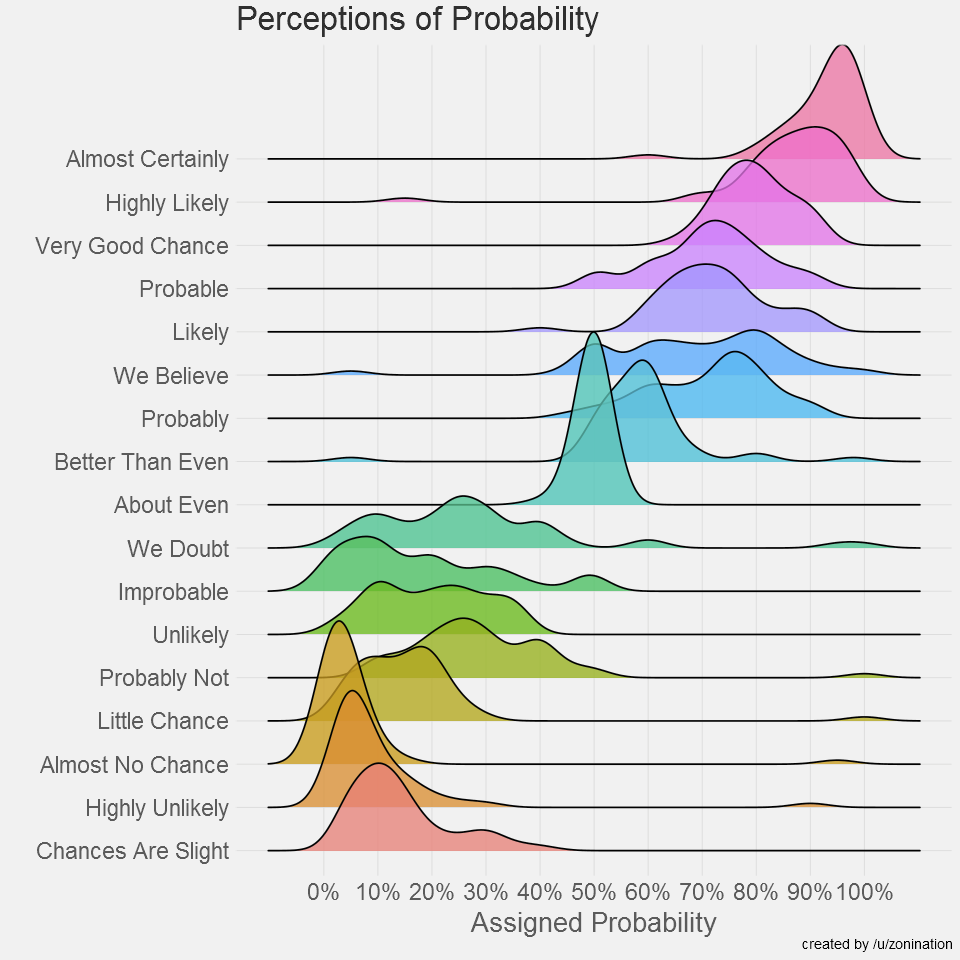
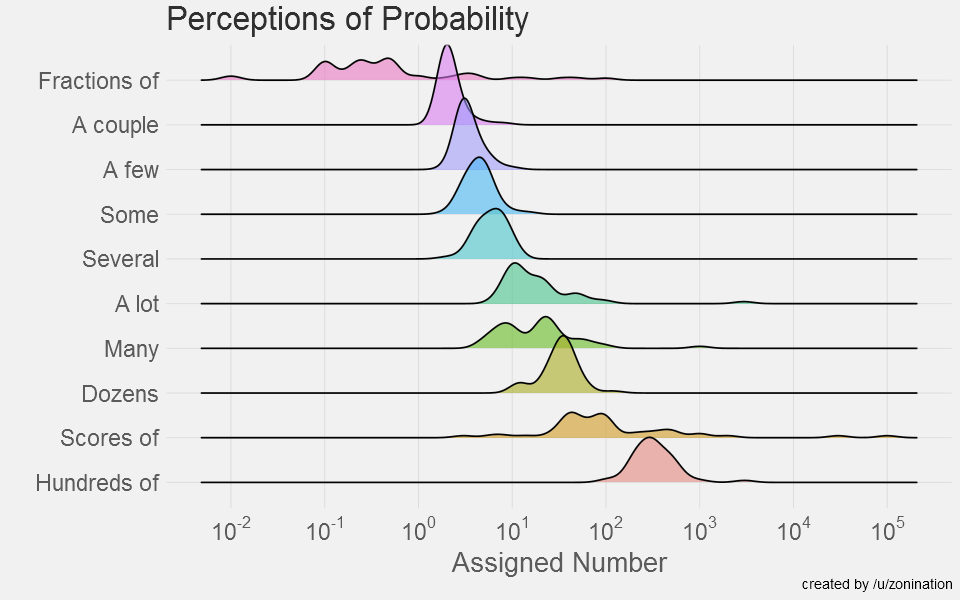
Full information on the data and visualisation process is on zonination’s Github.
In 2021, the research was repeated in my home country (the Netherlands), with Sanne Williams, a researcher from Leiden University, publishing the following for the Dutch language equivalent: